
Концепция
Данный проект посвящён исследованию возможностей генеративных нейросетей на примере обучения модели Stable Diffusion воспроизводить стиль детских рисунков.
В основе проекта лежит гипотеза о том, что нейросеть способна не только копировать визуальные паттерны, но и интерпретировать специфические особенности наивного художественного языка — такие как упрощённые формы, яркие цветовые сочетания и отсутствие академической перспективы.
Цель проекта — обучить модель генерировать изображения, визуально и стилистически близкие к детскому рисунку, сохраняя характерные черты «наивного» изображения мира.
Датасет


В качестве обучающего датасета были использованы собственные изображения — детские рисунки, выполненные от руки. В набор вошли изображения персонажей, животных, фантазийных существ, а также простых сцен с элементами окружающего мира: домами, природой и объектами.

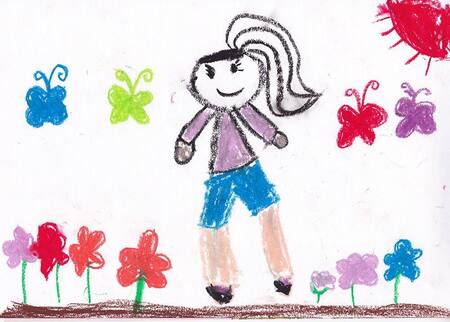





Процесс обучения
- Настройка среды Работа велась в Google Colab: установлены необходимые библиотеки (diffusers, transformers, accelerate), подключён GPU для ускорения вычислений.
2.Загрузка модели Загружена предобученная модель Stable Diffusion, которая использовалась как основа для дообучения.
Обучение модели (LoRA) Запущено дообучение с заданными параметрами (размер изображений, batch size, learning rate, количество шагов). Модель адаптировалась под стиль датасета.
Сохранение весов После завершения обучения сохранены веса LoRA для дальнейшего использования.
- Генерация изображений С помощью обученной модели сгенерирована серия изображений по текстовым запросам (prompt) с указанием нужного стиля.
Итоговые генерации
В результате обучения была получена серия изображений, сгенерированных нейросетью в заданном стиле. В серии представлены различные сюжеты: изображения животных, персонажей и простых сцен. Несмотря на разнообразие содержания, все изображения объединены единым визуальным стилем, который отсылает к исходному датасету. Нейросеть не просто копирует отдельные элементы, а генерирует новые композиции, опираясь на усвоенные закономерности.




Анализ результатов показывает, что модели удалось воспроизвести ключевые характеристики детского рисунка. В сгенерированных изображениях прослеживаются упрощённые формы, чёткие контуры, яркие и несмешанные цвета, а также наивная композиция без соблюдения классической перспективы. Особое внимание заслуживает передача персонажей: модель усвоила такие черты, как крупные головы, схематичные части тела и эмоциональная выразительность, достигаемая минимальными средствами.
Вывод
Для реализации проекта использовалась модель Stable Diffusion с методом дообучения LoRA (Low-Rank Adaptation). Процесс включал подготовку датасета, разметку изображений текстовыми описаниями, настройку параметров и обучение модели в среде Google Colab с использованием графического ускорителя. В ходе генерации применялись текстовые запросы с ключевыми словами, описывающими стиль, а также варьировались параметры генерации для получения разнообразных результатов.



