
Идея проекта
Проект посвящён исследованию возможностей генеративных моделей в воспроизведении авторского визуального стиля

В основе проекта лежит авторский стиль портретной иллюстрации, разработанный ранее для серии изображений приморских музыкантов в рамках другого учебного проекта.
Изначально этот стиль формировался для рок-исполнителей, из-за чего выглядит довольно мрачно и жутко. Визуальный язык строится на сохранении черт лица и общих человеческих пропорций, но с добавлением живописности и цветовых пятен, уходящих в синеву.
При этом создание одного портрета в данном стиле требует значительных временных затрат: детальная проработка формы, цвета и выразительности занимает длительное время и делает процесс трудоёмким.
В рамках проекта хотелось перенести этот стиль в генеративную среду. Основная идея заключается в том, чтобы исследовать, может ли нейросеть выступить в роли инструмента, способного воспроизводить и развивать уже существующий авторский визуальный язык.
Таким образом, генеративная модель рассматривается не как замена ручной работы, а как вспомогательный инструмент — средство ускорения процесса, поиска вариаций и генерации новых образов, а возможно и подложки, которая в дальнейшем может быть доработаны вручную.
Для обучения нейросети был собран датасет из 17 квадратных изображений размеров 512×512. Их не так много, поэтому изначально не было понятно, хватит ли этого для воссоздания стиля, однако стоило попробовать.




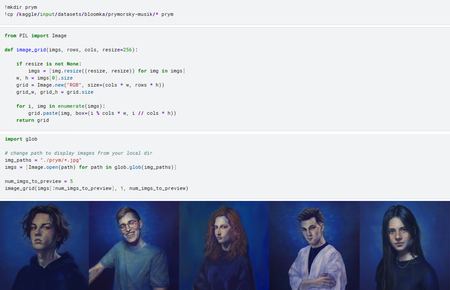
Первым этапом была настроена среда обучения: установлены необходимые библиотеки и загружен скрипт для дообучения модели Stable Diffusion XL с использованием метода DreamBooth и LoRA.
Далее был подготовлен обучающий датасет: изображения были скопированы в рабочую директорию и проверены с помощью предварительного просмотра. Это позволило убедиться в корректности данных перед началом обучения модели.
Также для каждого изображения были автоматически сгенерированы текстовые описания с помощью модели BLIP. К описаниям добавлен кастомный стиль (PRYMORSKYMUSIC style), после чего все данные были сохранены в файл metadata.jsonl, необходимый для обучения модели. После этого вспомогательная модель была удалена для освобождения памяти.
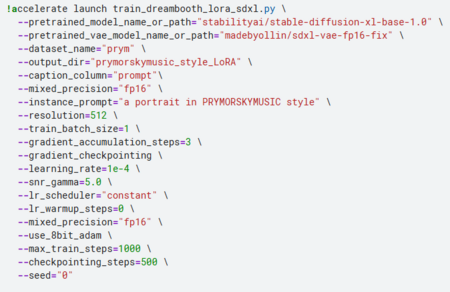
Предварительно настроив среду с использованием библиотеки accelerate и авторизовавшись в Hugging Face, проводилось обучение на базе модели Stable Diffusion XL с использованием метода DreamBooth + LoRA, что позволило адаптировать модель под авторский стиль без полного переобучения.
Ключевые параметры обучения:
Базовая модель: stable-diffusion-xl-base-1.0 Instance prompt: a portrait in PRYMORSKYMUSIC style Размер изображений: 512×512 Batch size: 1 Gradient accumulation: 3 Learning rate: 1e-4 Шаги обучения: 1000 Precision: fp16
Далее обученная модель была опубликована на платформе Hugging Face: был создан репозиторий, сформировано описание модели и загружены веса LoRA, что позволило обеспечить доступ к результатам обучения и их дальнейшее использование.
Финальным этапом обученная LoRA-модель была подключена к базовой модели Stable Diffusion XL и использована для генерации изображений по текстовым запросам. Полученные результаты сохранялись и использовались для формирования итоговой серии проекта.
Генерация изображений
Тестирование с простым промптом

Все промпты писались по одному принципу:
— Ключевой стиль — Характеристики персонажа — Дополнительные элементы
При первой генерации был использован промпт «a portrait in PRYMORSKYMUSIC style, young woman with long brown hair, wearing headphones», который уже выдал результат, соответсвующий моей стилистике.
Подобным образом я сгенерировала серию портретов с разными характеристиками, но в целом персонажи были похожи на оригинальных.


Сгенерированные изображения
Сгенерированное изображение
Полученные изображения в целом соответствуют исходному авторскому стилю, что проявляется в ряде ключевых визуальных характеристик:
В первую очередь, сохраняется общая структура портрета: композиция строится вокруг лица, которое остаётся центральным и наиболее проработанным элементом изображения.
Также модель успешно воспроизводит текстуру, характерную для исходных работ и хорошо выдерживает палитру и цветовые пятна.


Сгенерированное изображение / Оригинальное изображение
И всё же спустя какое-то количество генераций с помощью простых промптов стало заметно чересчур сильно сходство с оригинальными изображениями, что на первый взгляд говорит об ограниченности модели с точки зрения разнообразия.


Оригинальное изображение / Сгенерированное изображение
Усложнение промпта

Чтобы разнообразить генерации, было принято решение для начала поработать над содержанием промпта, усложнив и доработав его.
Я стала добавлять такие параметры, как возраст, поза, эмоция, аксессуары. Пример усложнённого промпта:
«a portrait in PRYMORSKYMUSIC style, elderly woman with gray hair and wrinkles, wearing earrings, gentle smile, calm face, straight posture»
Сгенерированные изображения
Таким образом действительно удалось достичь более интересного результата и получить новые типажи людей на портретах.


Сгенерированные изображения
Проблемные генерации
При написании более сложных промптов переодически возникали проблемы с отображением определённых черт, эмоций или действий, однако в контексте работы модели это не критично.


Плохо сгенерированные изображения
Эксперимент

Поскольку уровень генерации полностью устраивал и подходил под стилистику, заданную при обучении модели, захотелось попробовать создать что-то новое, отличающееся от предыдущего.
Так как среди оригинальных изображений были только портреты людей, было принято решение указать в промпте не мужчину или женщину, а разные виды животных, чтобы посмотреть сохранятся ли визуальные приёмы.
Пример промпта: «a portrait in PRYMORSKYMUSIC style, close-up of a white rabbit, ears up, looking slightly upward, alert expression»


Сгенерированные изображения животных
И действительно, нейросеть отлично справилась с генерацией животных, несмотря на отсутсвие примера в датасете, что говорит о пластичности модели.
Выводы
Лучшие сгенерированные изображения
В рамках проекта была обучена генеративная модель, способная воспроизводить авторский стиль портретной иллюстрации на основе ограниченного датасета.
Полученные результаты доказывают, что даже при небольшом количестве исходных изображений нейросеть способна уловить ключевые особенности визуального языка и применять их при генерации новых образов.
Также стоит отметить, что данный подход показал себя не только как эффективный вспомогательный инструмент, ускоряющий процесс создания визуального материала, но и как самостоятельный. Тем не менее наилучшего результата можно добиться комбинированией нейросети и ручной доработки
Использованные инструменты
Kaggle — обучение модели и работа с GPU https://www.kaggle.com
Google Colab — генерация изображений и тестирование модели https://colab.research.google.com
Hugging Face — хранение и публикация обученной модели (LoRA) https://huggingface.co
Описание применения генеративной модели: ChatGPT — помощь в отладке кода https://chat.openai.com



